6 min read
Using Aggregates and Combining Data Sources in OBIEE
Kimball defines “aggregate fact tables as simple numeric rollups of atomic fact table data built solely to accelerate query performance. These aggregate fact tables should be available to the BI layer at the same time as the atomic fact tables so that BI tools smoothly choose the appropriate aggregate level at query time. This process, known as aggregate navigation, must be open so that every report writer, query tool, and BI application harvests the same performance benefits.
A properly designed set of aggregates should behave like database indexes, which accelerate query performance but are not encountered directly by the BI applications or business users. Aggregate fact tables contain foreign keys to shrunken conformed dimensions, as well as aggregated facts created by summing measures from more atomic fact tables. Finally, aggregate OLAP cubes with summarized measures are frequently built in the same way as relational aggregates, but the OLAP cubes are meant to be accessed directly by the business users”, source here.
When working with Oracle Business Intelligence (OBIEE) you often have to deal with aggregates. OBIEE supports using and managing aggregates with Oracle BI Administration Tool in a very efficient way. In this and the following posts we will take a bit deeper look:
- How to model aggregates manually,
- How to use Aggregate Persistent Wizard and
- How to include Essbase as an aggregated store.
Let’s take a look at how to model aggregates manually. For our exercise, we will use Oracle Business Intelligence SampleApp VM (http://www.oracle.com/technetwork/middleware/bi-foundation/obiee-samples-167534.html).
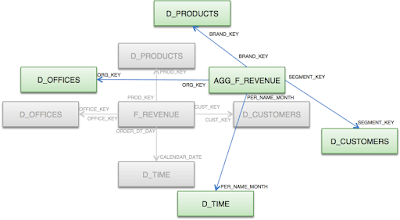
We will start with the following base data schema:
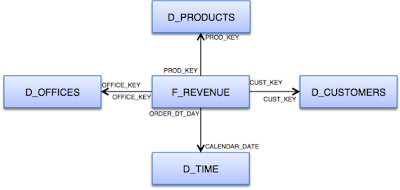
This data schema has already been imported into the BI repository (RPD), modeled in a physical model like this:
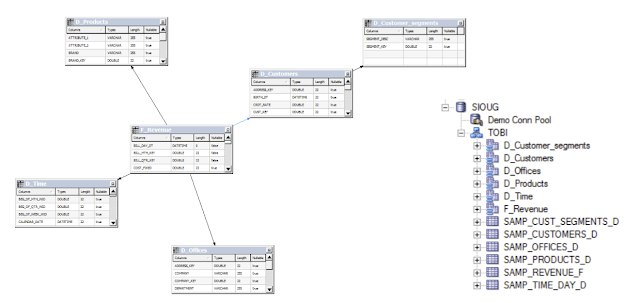
and business model which looks like this:
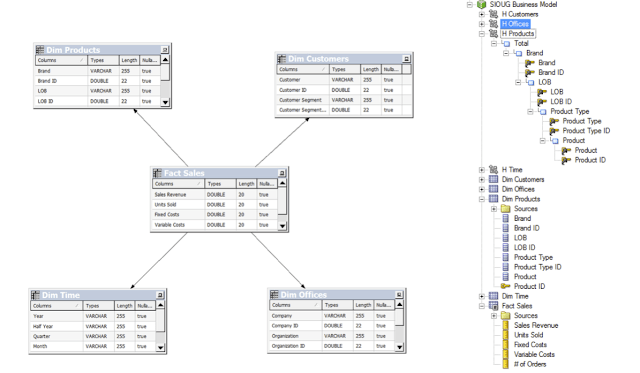
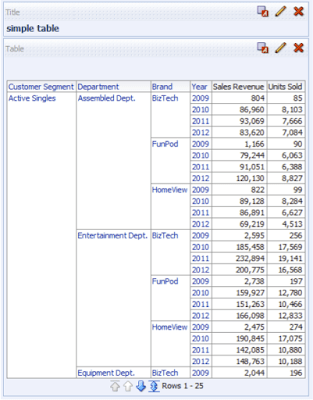
If we create and run a simple query:
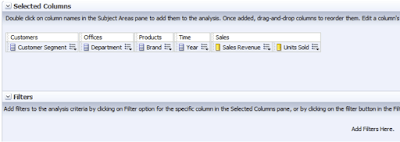
this would be the result table:
Execution log (nqquery) shows the following SQL was executed:
WITH SAWITH0 AS (select sum(T4535.UNITS) as c1,
sum(T4535.REVENUE) as c2,
T4488.SEGMENT_DESC as c3,
T4510.DEPARTMENT as c4,
T4522.BRAND as c5,
T4563.PER_NAME_YEAR as c6,
T4510.DEPT_KEY as c7,
T4522.BRAND_KEY as c8,
T4488.SEGMENT_KEY as c9
From SAMP_TIME_DAY_D T4563 /* D_Time */ ,
SAMP_PRODUCTS_D T4522 /* D_Products */ ,
SAMP_OFFICES_D T4510 /* D_Offices */ ,
SAMP_CUST_SEGMENTS_D T4488 /* D_Customer_segments */ ,
SAMP_CUSTOMERS_D T4491 /* D_Customers */ ,
SAMP_REVENUE_F T4535 /* F_Revenue */
where ( T4488.SEGMENT_KEY = T4491.SEGMENT_KEY and T4491.CUST_KEY = T4535.CUST_KEY
and T4510.OFFICE_KEY = T4535.OFFICE_KEY
and T4522.PROD_KEY = T4535.PROD_KEY
and T4535.ORDER_DAY_DT = T4563.CALENDAR_DATE )
group by T4488.SEGMENT_DESC, T4488.SEGMENT_KEY, T4510.DEPARTMENT, T4510.DEPT_KEY, T4522.BRAND, T4522.BRAND_KEY, T4563.PER_NAME_YEAR)
select …
No surprise there, right? Data is read from “base” tables as expected. Ok. Let’s bring finally some aggregates in. For each table in our base data model, we need to create aggregated table at the required aggregation level. Let’s say that we want to aggregate our data at the following levels:
- Product dimension at Brand level
- Office dimension at Organisation level
- Customer dimension at Customer Segment level
- Time dimension at Month level
- Revenue fact table at dimension levels listed above.
Note that it’s necessary to aggregate dimensions too, not only tables.
Here are the required SQL scripts to create aggregated tables above:
create table samp_revenue_f_agg as
select p.brand_key, s.segment_key, o.org_key, t.per_name_month, sum(f.revenue) revenue, sum(f.units) units, sum(f.cost_fixed) cost_fixed, sum(f.cost_variable) cost_variable, count(f.ORDER_NUMBER) orders
from samp_revenue_f f, samp_products_d p, samp_customers_d c, samp_cust_segments_d s, samp_offices_d, samp_time_day_d t
where p.prod_key = f.prod_key
and s.segment_key = c.segment_key
and c.cust_key = f.cust_key
and o.office_key = f.office_key
and t.calendar_date = f.order_day_dt
group by p.brand_key, s.segment_key, o.org_key, t.per_name_month
order by p.brand_key, s.segment_key, o.org_key, t.per_name_month;
create table samp_time_day_d_agg as
select distinct d.per_name_month, d.per_name_qtr, d.per_name_half, d.per_name_year
from SAMP_TIME_DAY_D d
group by d.per_name_month, d.per_name_qtr, d.per_name_half, d.per_name_year
order by 4,3,2,1;
create table samp_products_d_agg as
select distinct p.brand, p.brand_key
from SAMP_PRODUCTS_D p
group by p.brand, p.brand_key
order by p.brand, p.brand_key;
create table samp_customers_d_agg as
select distinct s.segment_key, s.segment_desc
from samp_cust_segments_d s
order by s.SEGMENT_KEY,s.SEGMENT_DESC;
create table samp_offices_d_agg as
select distinct o.organization, o.org_key, o.company, o.company_key
from SAMP_OFFICES_D o
group by o.organization, o.org_key, o.company, o.company_key
order by o.organization, o.org_key, o.company, o.company_key;
Once we have aggregated tables created, these can be imported into RPD. Similarly, as with base tables, once imported, aggregated tables have to be modeled on a physical level.
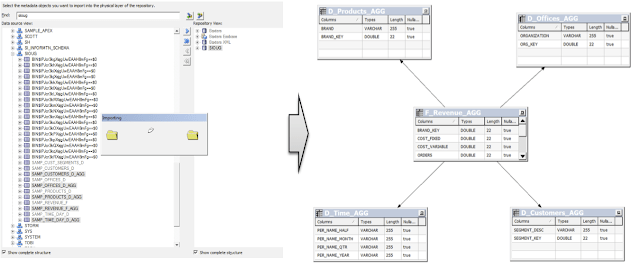
Now, we need to tell OBIEE that new aggregated tables should be used instead of base tables if that is more efficient to execute queries. The other requirement not mentioned so far, but equally important, is that end users are not affected by any changes made (with the exception that queries are run much faster).
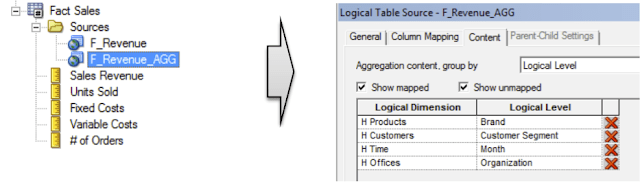
The business model should not change … much. Changes are made at Logical Table Sources where additional logical table sources and new aggregated tables are just added.
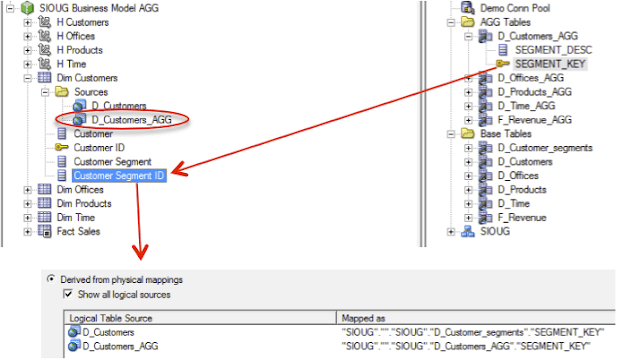
You can simply drag and drop physical columns onto existing logical columns. A new logical table source in this case will be automatically added and this logical column will have now mapped to two logical table sources. What we need to define is to define the logical level for each logical table source.
Which logical table source to use is also defined at fact table when we define logical levels:
Let’s test it. Create the same query as before:

and run it to get the following result, the same as initially:
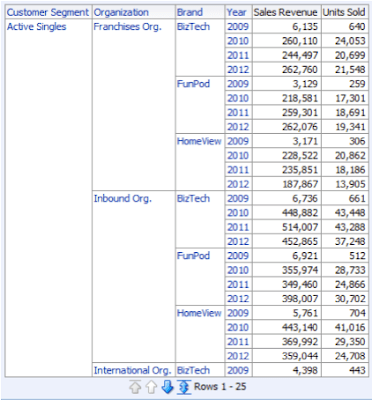
Check logs again. Observe that SQL which has been generated and executed is now reading from aggregated tables:
WITH SAWITH0 AS (
select sum(T5346.UNITS) as c1,
sum(T5346.REVENUE) as c2,
T5337.SEGMENT_DESC as c3,
T5340.ORGANIZATION as c4,
T5343.BRAND as c5,
T5355.PER_NAME_YEAR as c6,
T5337.SEGMENT_KEY as c7,
T5340.ORG_KEY as c8,
T5343.BRAND_KEY as c9
from
SAMP_TIME_DAY_D_AGG T5355 /* D_Time_AGG */ ,
SAMP_PRODUCTS_D_AGG T5343 /* D_Products_AGG */ ,
SAMP_OFFICES_D_AGG T5340 /* D_Offices_AGG */ ,
SAMP_CUSTOMERS_D_AGG T5337 /* D_Customers_AGG */ ,
SAMP_REVENUE_F_AGG T5346 /* F_Revenue_AGG */
where …
If you want to drill down and click on one of the possible drill columns:
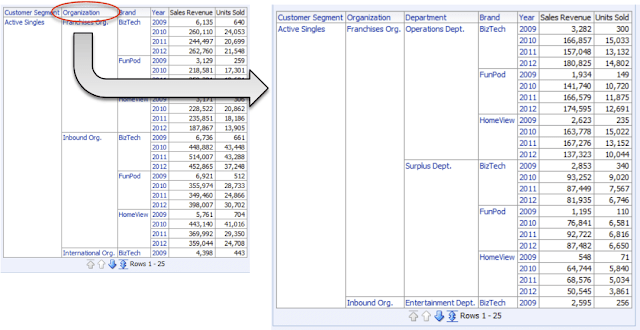
In this case, data is seamlessly read from base tables:
This concludes our first post on how to use aggregates in OBIEE. In the following post, we will take a look at how to use Aggregated Persistence Wizard and how to use Essbase as our aggregated data store.