10 min read
Cloud Economics – Spot Pricing
Cloud Economics Part #2: Some Thoughts On The ‘Spot’
If you missed the first instalment in our Cloud Economics series, please click here to catch up on our discussion of whose responsibility is it to manage your Cloud expenses and control spend excesses and how to avoid the financial sting in the tail of Public Cloud services.
Cloud economics are complicated.
The plethora of pricing and provisioning options available mean that it’s often difficult to understand what’s available to you, and what might be the best option for your particular use case. Furthermore, even with standard offerings, it’s possible that localised and decentralised operational nuances provide additional layers of complexity. Conversely, though, such diverse dynamics might also provide commercial opportunity.
As an example, let’s look at and expand on, a recently provisioned (H2 2018) academic paper investigating the distribution of Amazon EC2 instance spot pricing.
First off, some background and explanations.
One of the standard offerings from Amazon Cloud Services is EC2 – delivering Infrastructure as a Service (IaaS) – i.e. renting servers.
Such services can be provided based on many variables, and the servers vary in the resources they provide and consume – in terms of CPU sizes, memory, geographical location, multi or single tenancy, resilience capability, transience and so on.
As well as the many provisioning options available, there are also different ways of purchasing your required resource.
Standard pricing is pay as you go – on-demand, usually by the hour or second depending on the instance secured.
Reserved instance pricing brings a ‘loyalty’ bonus – if you know that you need an instance on a long-term, steady or predictable state, then making a larger commitment to pay brings significant benefit. You can for example, pay for an entire year, or three, and make that payment partially or in-full up front, for additional discounts.
One of the less mainstream provisioning options is Spot Pricing, the topic of the academic paper referenced above. It’s a particular provisioning mechanism which might be viewed in a somewhat contrary fashion to Reserved Pricing – it makes use of spare cloud capacity, and can provide this at extremely high discount levels, based on trends in supply and demand. Spot prices update on a regular basis. (Note this isn’t necessarily the same as saying that the prices change regularly – more on this later).
Requests are usually based on the maximum price that you’re willing to pay for the instance type you need, and if the current published spot price is less than your maximum, then your instance is created (assuming the capacity is available).
However, should EC2 need the capacity for guaranteed purposes, or demand changes the Spot price above your maximum, or Spot capacity reduces, then your Spot instance will normally be ‘interrupted’ at two minutes’ notice. You and your application need to cater for that.
Instances can sometimes achieve up to 90% discount and would therefore seem to be a great deal – but due to the ‘interrupt’ behaviour such instances would normally only be used in specific use cases. Where applications are fault tolerant, have high degrees of restart capability, or are non-critical, spot instance pricing can bring significant financial benefit. Development and non-production applications might therefore be extremely well suited to make use of such instances. Other nuances in spot instance capability add flexibility and tolerance, with the penalty of reduced discount.
One thing to note before we progress – we’re just looking at pricing of the EC2 instances here – not any supplementary licensing costs – e.g. Oracle or Microsoft Licenses – you might want to review some of the other blogs in our AWS series (CPU Optimisation and Licensing Oracle on AWS – An Independent Review).
Ok, back to the spot instances and the academic view – prices are updated regularly based on trended supply and demand. The reviewers wanted to understand if there were particular trends over a time frame, with respect to the Geographical location of the launched spot instances – could any useful, exploitable insights be achieved looking at Spot Instance Data in the EU geography compared to the US, Asia Pac, Canada, and additionally across a particular region’s Availability Zones (AZ), or inter geography domain – eu-central-1a versus eu-central-1b for example or eu-central-1a versus eu-west-1c?
The researchers used standard AWS API/CLI calls to retrieve a set of over 4 million data points for analysis, and concentrated on the following principal areas of analysis:
- Average price analysis across all instance types within a region across all timed data
- Average price analysis for each instance type in a region
- Analysis of frequency of prices per instance in particular AZs in the region
- Cross comparisons of these analysis groups
So, what did they find? (I’ll mostly reference the papers researched calculations rather than refresh with current data unless noted otherwise, and whilst some examples refer to currently unavailable previous generation instances, the logic still applies).
- There are indeed savings to be made – the overall average spot prices per main instance type in a region are much less than the on-demand prices, even smoothed over several months and across AZs in a region or geography, and irrespective of time of day. For instance, the current (EU Ireland) On Demand price of a Windows m4.large instance is $0.203 per hour, and for Linux $0.111. The current spot prices are $0.1264 and $0.0344. The researchers calculated a general average of $0.052 (over 60 days, 24 hours and all AZs in the EU geography). That’s quite a reduction.
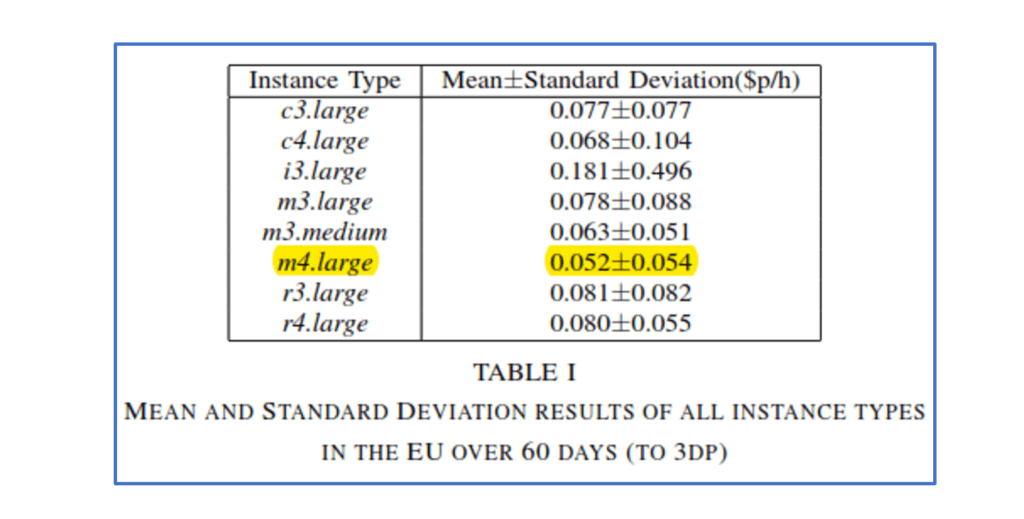
- There is significant variance in average price for a specific instance type depending on the regions chosen. The m4.large instance average in the EU domain was $0.052, in the US $0.084, $0.089 in AP and $0.027 in Canada. If your application warrants it, then Canada would appear to be one of the cheapest places to launch instances (although it does appear to have less instance types available to Spot creation, and somewhat more volatility). Note however that not all instance types show consistent behaviour in a region or geography – some are more expensive than others, so don’t assume that a particular instance price will always be cheaper (or more stable).
| Geography | Instance | Mean +/- SD |
| EU | m4.large | 0.052 +/- 0.054 |
| US | m4.large | 0.084 +/- 0.118 |
| AP | m4.large | 0.089 +/- 0.067 |
| CA | m4.large | 0.027 +/- 0.032 |
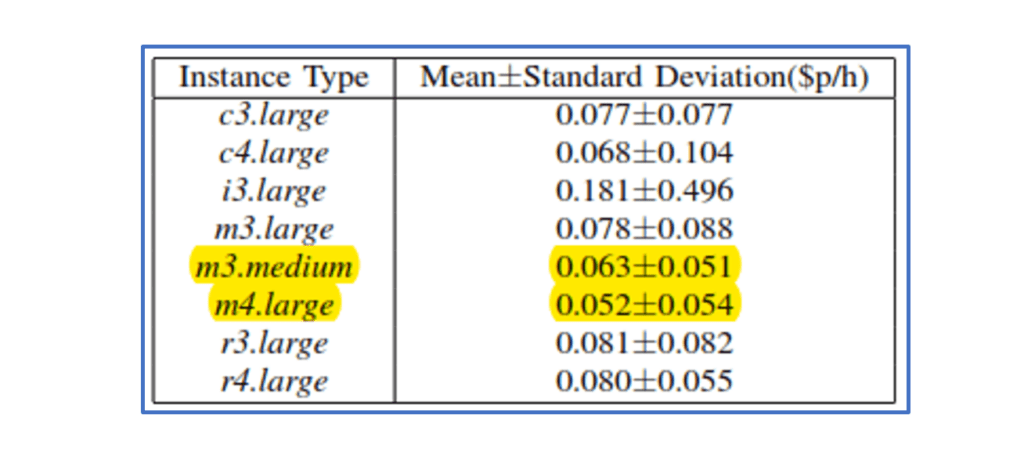
- Volatility varies across the data – where volatility (as measured by standard deviation of the prices) is low, this indicates that prices tend to stay closer to the average – in other words the spot price doesn’t alter significantly – if this is the case, then you’re more likely to be able to satisfy your spot requirement needs regularly – without termination of the instance – i.e. higher stability. The point, is – more stability. The prices of certain instance types within a particular region or geography appear to be very ‘stable’ (low standard deviation). Match this with a low average price when compared to On Demand pricing, and you have a potentially very cheap rarely terminated alternative instance provision to the normally used one.
- The instance that works for you might not be the one you originally thought – someone who might normally only be able to afford an m3.medium instance (1 vcpu, 3.75Gb memory) could be better off launching an m4.large (2 vcpu, 8Gb memory) in the EU. It’s cheaper, even with the slightly higher volatility, and depending on the workload and application, could get more work done in less time.
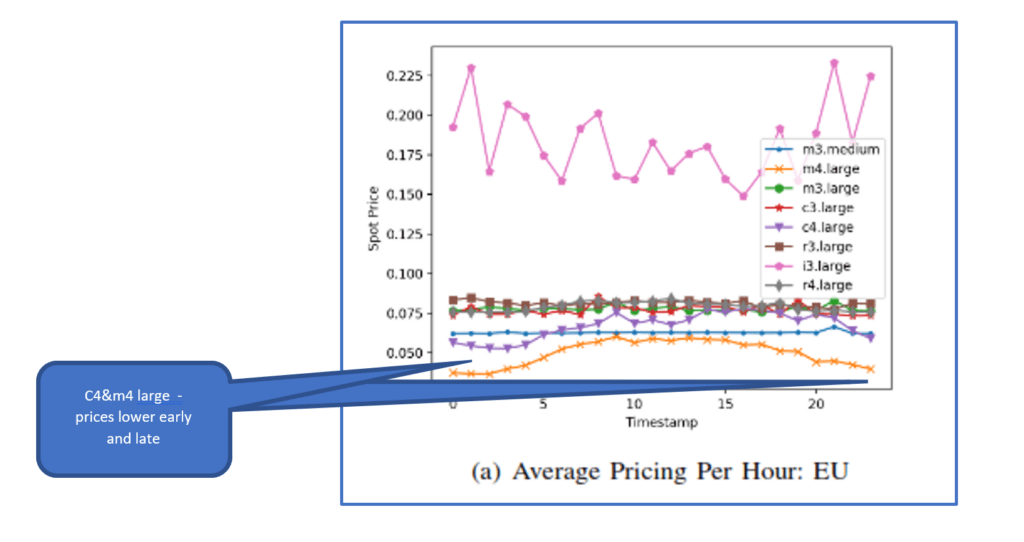
- Time of day might also provide advantages – even in the EU, where prices are generally smoother, there are indications of lower prices in the early hours of the morning and late at night – when there is less general demand – for c4 and m4 large. If you have workloads that can run overnight then there are advantages to be had. Even if not, overnight in one region is daytime in another, so cross regional opportunities exist.
- Taking this out further, specific days of the week seem to offer advantages – again, though the EU seems to have a smoother overall workload, weekends have lower prices for certain instance types – m4.large and r4.large for example. In the US m4.large and c4.large have even greater reductions at the weekend. There are less indications of weekend opportunity in Canada, but this is very possibly down to the fact that there isn’t an overall smoothing – there’s not as high a volume of availability or use to show a regular trend (but don’t forget that Canada offered up one of the best overall price opportunities anyway, so perhaps scheduling at specific times isn’t a problem here). Conversely, i3.large instances have higher prices and much higher volatility in the EU so less opportunity there for savings – the US or AP offer better price points for these instance types, though volatility is still an issue – so the chance of termination may be higher.
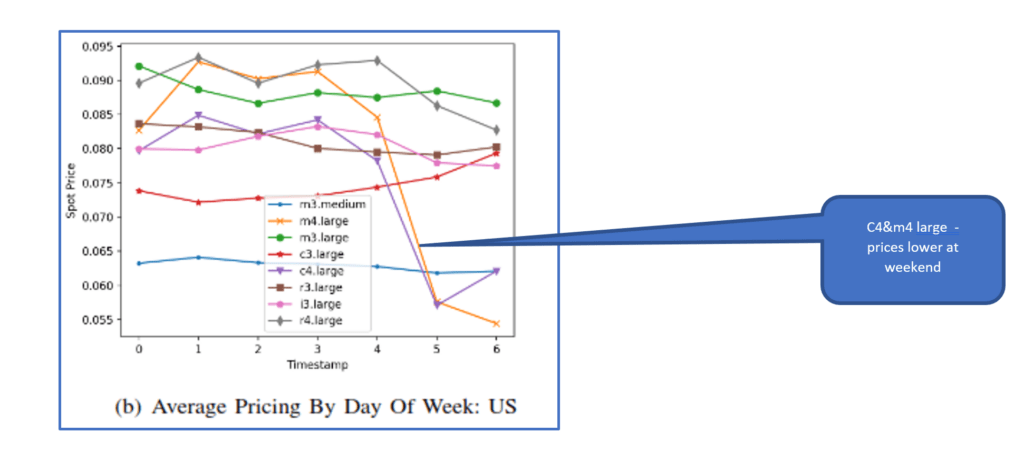
- Analysing each individual instance type over a day or week period for each region also backs up some previous observations – Canada shows consistently stable low pricing for the instances it has available. And whilst c3.large and r3.large instance types show elevated levels of volatility and cross region variation – if you ‘upgrade’ to the c4 or r4 then prices are similar but less likely to be terminated – if job / application completion is a factor. M3.medium instances show consistent weekly pattern – cheaper at the weekend irrespective of region.
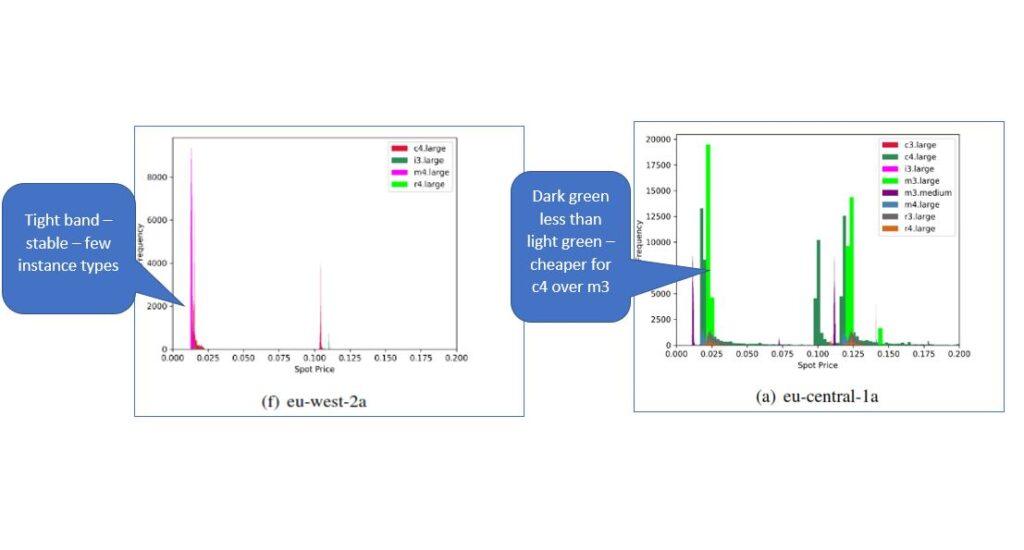
- Within regions themselves there is variation across availability zones – for example, of the 6 AZs analysed in the EU, very few instance types were launched on a spot basis in eu-west-2a (London) and if you wanted an m4.large its pricing was highly stable. Similarly, in eu-central (Frankfurt), you’d get better pricing launching a c4.large than an m3.large (compute optimised over general purpose). Here you can start to look for advantages in particular AZs if you have data protection requirements that demand specific data storage location.
There are some interesting insights here – which suggest some other thoughts that might be worth investigating further:
- The current analysis doesn’t distinguish across base instance type (Windows, Linux/Unix, etc) – where prices vary. There may therefore be additional insight gained into how this is affected across time and geography, and where particular instance types of interest might be obtained more effectively.
- Instance family impact – the “i” family are storage optimised instances, “c” compute optimised, “r” memory optimised, and “m” general purpose. The “i” instances seem to have the higher levels of volatility – is the storage variable more prevalent overall to spot calculations in this case (rather than CPU or memory)?
- Seasonal variation – whilst only 60-90 days of data are currently available it would be interesting to store and analyse data on wider time ranges – might be see trends for end quarters in the EU, holidays in the US?
- Whilst we’ve noted that the instance needs to be fault tolerant to a degree, there is of course the option of hibernation and stop/start of the instance (along with the spot request being one-time or persistent) – so you could achieve only minor interruptions in your application. Naturally, these variables will affect the supply demand dynamics and therefore the price you pay.
- Canada seems to have low overall demand, and therefore very good pricing – might we see similar in the recently launched South America region? Whilst China region is also relatively recent, it may well be swamped with requests – still, analysis of specific instance types might again yield insight. (Note you need a specific account for AWS (China) resources).
- Prices are updated every five minutes on the AWS Spot pricing pages (but might not change for a long time depending on the supply and demand dynamics).
- Dedicated host – some specific instance types are available on a dedicated host basis as spot requests – should your application demand it.
- Specifying instance duration – anything between 1 and 6 hours – can guarantee you more up-time but could adversely affect the price available.
- On a more complicated basis, and again, depending on the application type or functions that you need to perform (or rather the types of instances that you could use to do this), you have further variables to play with by using things like spot fleets and/or instance weighting. Again, these affect the dynamics of the spot calculation compared with basic single instance requests but provide significant flexibility in where you might provision an instance or instance group with a particular set of requirements.
I could go on, but you begin to see that spot pricing is an interesting area of focus. Depending on your application need (data requirements, availability), and its ability for pause/ restart/ refresh/ recreation, you might gain significant savings by considering spot instances. Some of the additional points above can’t be analysed at this point, due to a limitation on the variables available publicly, but this might change in the future.
Amazon publishes summarised information on spot dynamics (savings achieved and interruption frequency over the previous 30 days), and you can gain insight into your own savings over standard pricing from the AWS console.
We’ve looked specifically at AWS spot pricing here, but Azure provide similar with low-priority VMs as does Google with preemptible VMs, and IBM with transient virtual servers.
Who said going to the Cloud would be simple?…
As always, if you have any comments or queries, get in touch with Version 1 using the form below.
If you missed the first instalment in our Cloud Economics series, please click here to catch up on our discussion of whose responsibility is it to manage your Cloud expenses and control spend excesses and how to avoid the financial sting in the tail of Public Cloud services. Stay tuned for our next instalment in the Cloud Economics series.